evaluagent Launches Context Engine: AI Quality Assurance that validates whether agents give the right answer
15 April 2026
AI quality assurance that evaluates conversations against your own policies, knowledge base, and business rules – not generic criteria
Middlesbrough, UK – evaluagent, the AI-powered quality assurance and conversation intelligence platform for contact centres, today announced the launch of Context Engine. This new capability automatically evaluates whether agents give not just a good answer but the correct answer, by grounding every AI score in a customer’s own policies, processes, and knowledge base.
Automated quality assurance has transformed how contact centres monitor performance. Tools like AutoQA now score every interaction, not just a sample, accurately and consistently across tone, empathy, compliance, and process adherence.
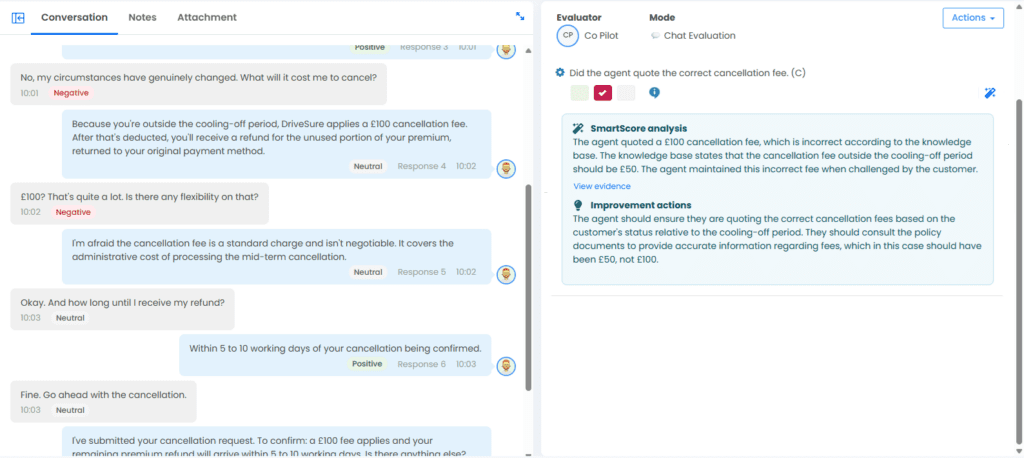
But there has always been a gap: whether the agent gave the customer the right information. A conversation can score well on every standard metric and still contain a factual error that leads to a complaint, a lost customer, or a regulatory finding.
“We built AutoQA to give contact centres objective, scalable quality scores,” said Matt Jones, Head of Product of evaluagent. “It gave teams more insight than they’d ever had, but the missing piece was whether agents were giving the right answer. Context Engine solves that.”
Context Engine works through two components:
- Company Information lets customers configure their industry, region, and business objectives, giving the AI a baseline understanding of their operation.
- Knowledge Vault lets customers upload product guides, policies, and compliance documentation, and attach them directly to scorecard line items – flagging automatically when an agent’s response contradicts the company’s own rules.
The difference is immediate. An insurance agent who skips a mandatory step on a comprehensive renewal policy passes a standard quality evaluation. With Context Engine, the AI checks the conversation against the correct process for that customer’s cover level and flags the gap – before it becomes an issue.
Beta customers tested Context Engine ahead of general release, with impressive results. Alignment between AI scores and human evaluator outcomes improved measurably, and customers reported that the difference in evaluation quality was clear from the first use.
Elizabeth Gunn, Product Manager at evaluagent, added: “This is all about giving customers the ability to provide AI scoring context. The quality of an evaluation depends entirely on the knowledge behind it – Context Engine provides that, meaning AI scoring gets even closer to that of your best QA evaluators. That frees up the human team for more valuable activity, like deeper reporting and agent coaching.”
For contact centres where accuracy carries real consequences – regulated industries, complex product lines, high-stakes conversations – Context Engine makes it possible to evaluate what has always mattered most and has never been possible to automate before.
Learn more at www.evaluagent.com/context-engine