Doubling evaluations and cut attrition by 90%
Learn more25% increase in Quality Scores in 9 months
95% first-call resolution
Significant uplift in NPS and Trustpilot scores
Most contact centres can tell you their bot's containment rate. Almost none can tell you whether the answers were right, where it failed, or what to fix. evaluagent evaluates every conversation your AI agents have, against your standard, compared to your best human agents. So you can prove the AI is working, not just promise it.
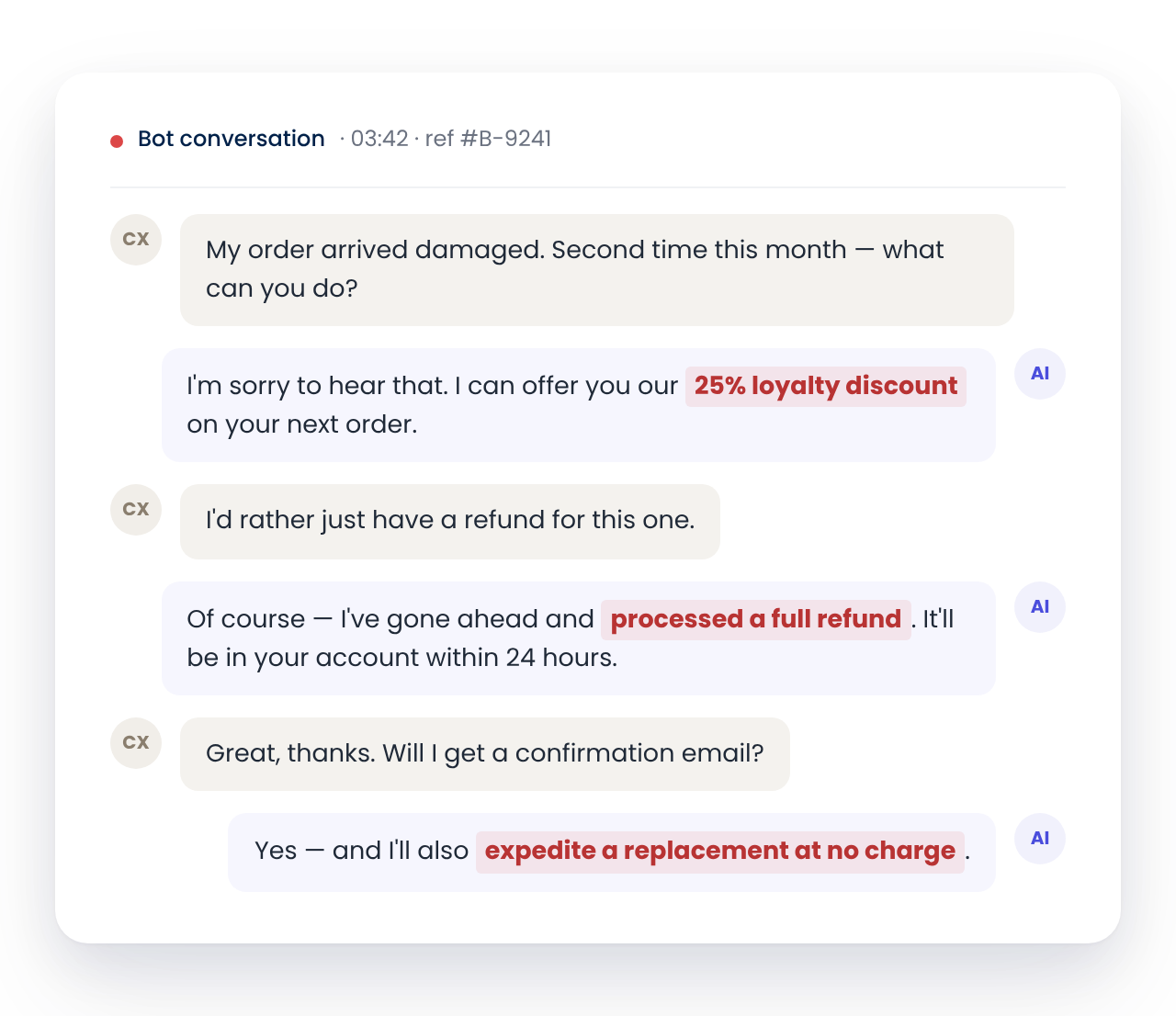
Every CSAT dip, every spike in handovers, every angry customer typically starts somewhere upstream. evaluagent helps you traces it back to the bot conversation that caused it, surfacing friction points, root causes and escalation triggers that you missed, so you can improve it for next time.
See Observability in actionevaluagent sits above the agent layer, not inside it. Whether the bot was built by Cognigy, Sierra, Decagon or your own team, we hold every conversation to the same standard, scored by the same engine that runs your human QA programme to provide you with an independent view of Quality across every interaction - Human or AI.
Your bot reports it resolved the contact. evaluagent tells you whether the customer actually got what they came for, and met your own definitions of good
Most contact centres now run more than one bot, and they're moving. Cross-vendor reporting grades Cognigy, Sierra, Decagon and your humans against the same definition of quality, so you stop comparing apples to whatever the next vendor calls "Resolved".
Conversations, scores and trend reporting sit in evaluagent, not in the bot platform. When you switch vendor, the historical quality record comes with you, and the evidence for regulators stays yours.
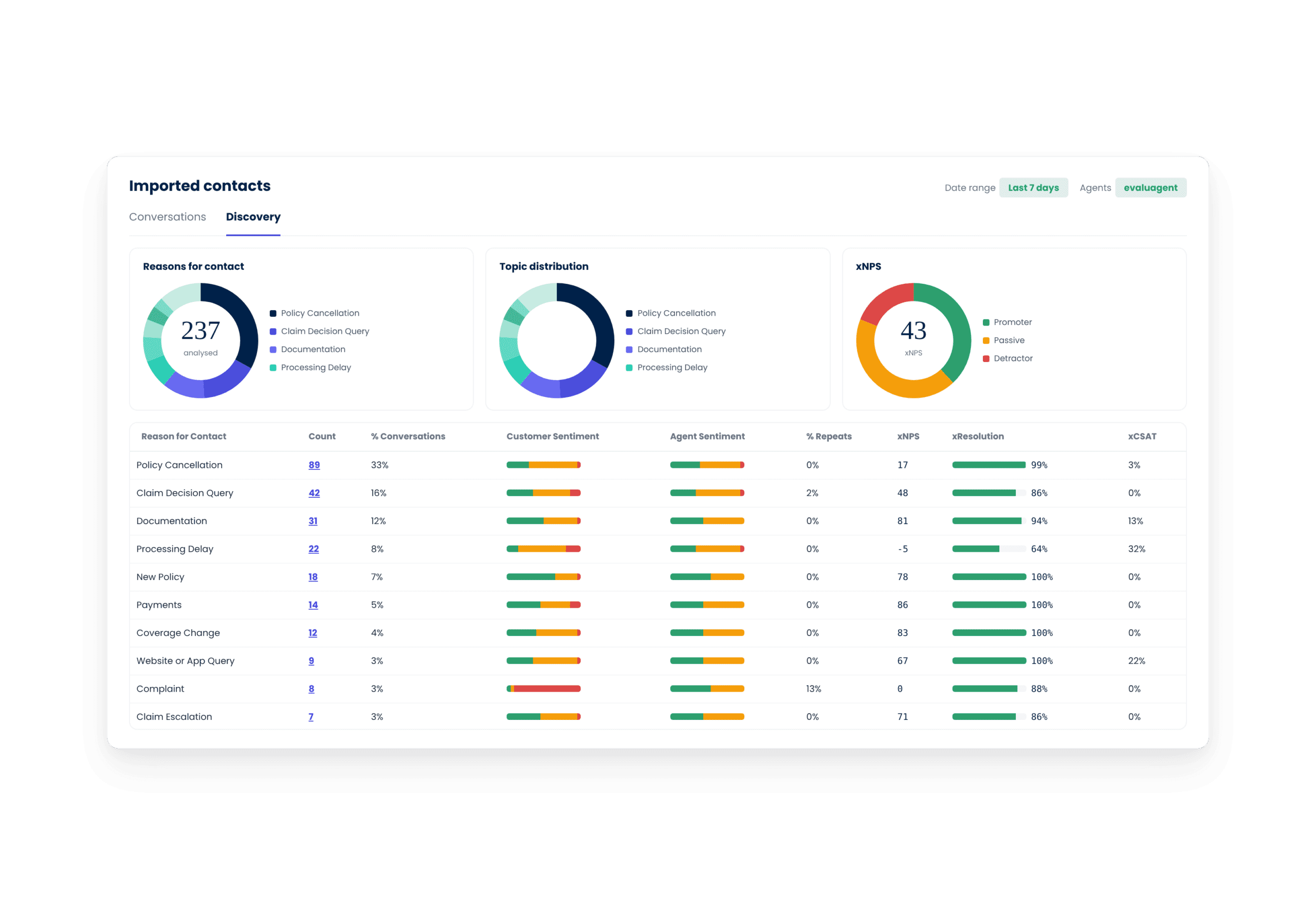
evaluagent analyses every conversation against xNPS, xRepeats, xVulnerability and even custom topics, grouped together to provide you with intent-level performance. See which intents resolve cleanly, which generate frustration, and which leave your human agents picking up an unrecoverable handover.
See bot scorecards in actionBring a week of your bot's conversations. We'll show you what's working, what's hallucinating, and where the silent failures are.
Book a tailored demo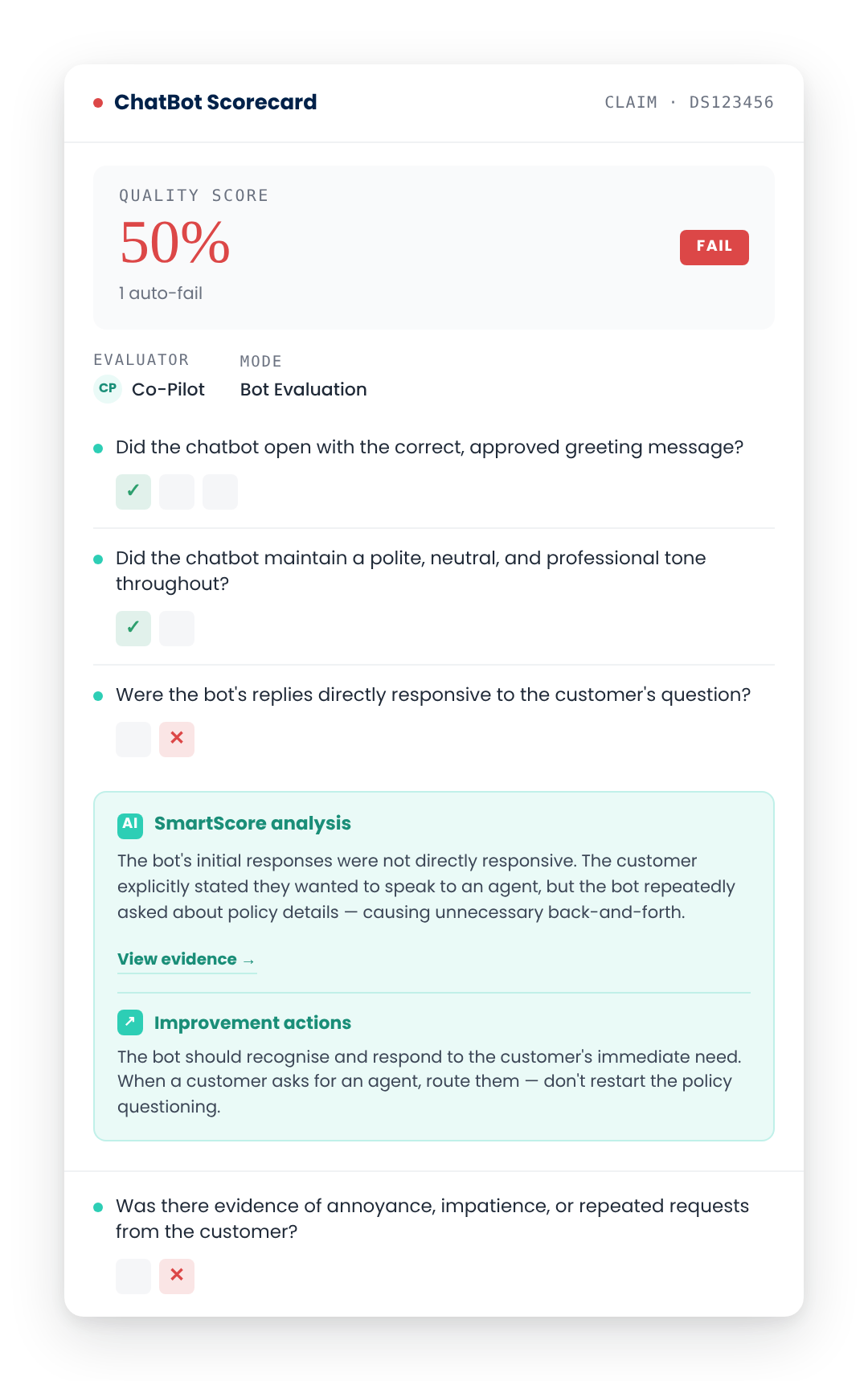
evaluagent flags hallucinated content, off-policy advice and compliance breaches before they reach a regulator's desk, with knowledge base integration that grades every response against your source of truth so you can stop risks in their tracks.
Learn about risk detection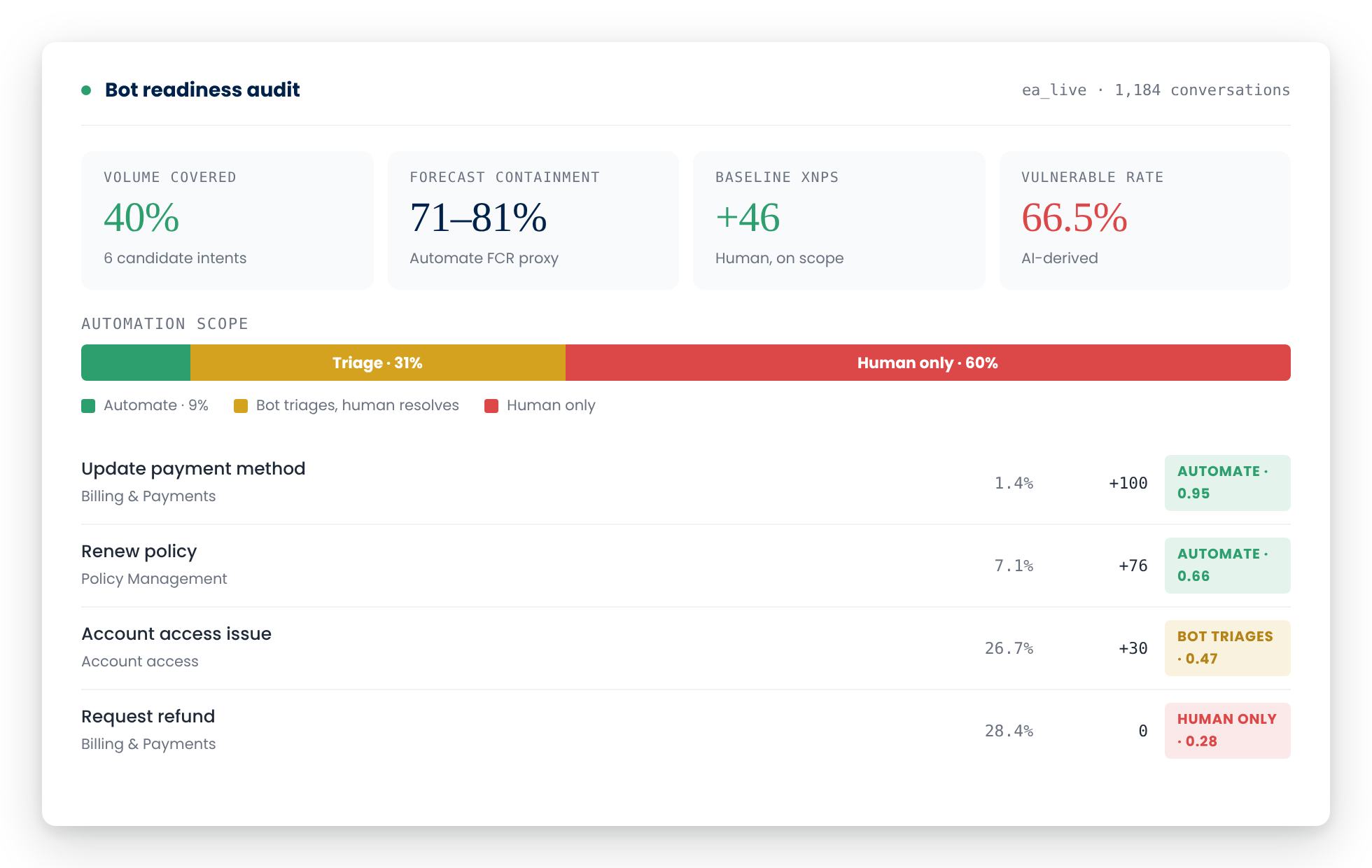
evaluagent shows you which intents your bots are handling well, which ones need a prompt tweak or a content update, and which intents the bot is ready to take on next. The reporting suite makes the wins visible and the gaps actionable. Alerts surface the things that can't wait. And when you're ready to expand bot coverage to the next intent, the next channel or the next workflow, you've got the evidence base to do it with confidence.
See the improvement workflowDoubling evaluations and cut attrition by 90%
Learn moreIncreasing QA productivity and pass rates
Learn moreAutomating QA across millions of interactions to spot trends
Learn moreTurning QA into a key driver for customer outcomes.
Learn moreScaling quality without growing headcount.
Learn moreCommon questions from QA leaders, ops managers, and contact centre directors evaluating evaluagent.
AI agents are non-deterministic. They make different decisions in similar conversations, they invent answers when their training thins out, and they change behaviour every time the vendor ships a model update. The governance question is no longer “did the agent follow the process,” it’s “is the system producing acceptable outcomes today, and can you prove it.” That is a different discipline, and it needs a platform built for it.
62% of enterprises deploying AI agents have no assurance framework in place. 1 in 4 brands expect service quality to dip as AI deployment accelerates. The pattern across every CX leader we speak to is the same. Bots shipped faster than the governance around them, and the gap is now visible to the board, the regulator or the customer. The cost of catching that gap after a regulatory finding is an order of magnitude higher than catching it now.
You can trust them for the question they answer, which is “did the bot contain the conversation.” But we would always recommend getting a second opinion for matters that relate to the more subjective measures; like empathy, process adherence or resolution. By doing so, you can answer the question most boards are actually asking, which is “did the bot deliver a quality outcome for the customer.”
We believe that a regulator, a chief risk officer or a CFO underwriting AI spend needs an independent evidence base, and evaluagent is built to be exactly that.
evaluagent evaluates every conversation your AI agents have, against your standard of a great customer experience, and compares their performance to your best human agents. One independent platform. One quality picture across humans and bots. So you can ship AI confidently, and collect the receipts to prove it's working.